

0. 배경
AI 연구를 하며 여러 서버를 사용하게되고 OS를 넘나드는 일이 많게 된다.AI에 사용되는 데이터 및 결과 파일은 용량이 매우 크기 때문에 클라우드 저장소를 활용에는 한계가 있다.
기존에 필자는 putty와 MobaXTerm와 같은 Tool들을 통해 ssh/ftp를 이용하여 서버에 접속하여 파일을 접근 해 왔었다.
물론 이러한 Tool들은 사용하기 간편하고 편리하지만 folder 구조의 native UI 형태로 좀 더 직관적이게 사용하고 싶었다.
이러한 문제를 해결 해 줄 방법으로 Server Message Block (SMB) 프로토콜을 Linux에서 구현한 Samba를 소개한다.
1. Samba 설치
$ sudo apt-get install samba
 |
| 실행 결과 |
2. Samba 계정 추가
$ sudo smbpasswd -a USERNAME
 |
| Samba의 USERNAME과 PASSWORD 설정 |
3. Config 설정
$ sudo vi /etc/samba/smb.conf
위 명령어를 실행 후 아래 정보를 맨 밑에 추가해준다.
[SHARE] comment = Howard's home directory path = PATH_TO_SHARE valid users = USERNAME writable = yes browseable = yes create mask = 0644 directory mask = 0755
4. Ubuntu에서 Linux 서버 접근

Ubuntu18.04부터는 위와같이 간단하게 접근할 수 있다.
'서버 주소 입력...'란에 smb://SERVER_IP를 적어주면 끝
Ubuntu 18.04보다 낮은 버젼을 사용하거나, 본인이 원하는 위치로 mount하고 싶을 경우 아래 명령어를 terminal에 입력하면 된다.
$ sudo mount -t cifs -o username=${USERNAME},pass=${PASSWORD},iocharset=utf8,uid=${UID},gid=${GID} //${SERVER_IP}/${SHARE} ${LOCAL_PATH}
- USERNAME: 2.에서 만든 samba 계정 정보
- PASSWORD: 2.에서 만든 samba 계정 정보
- UID: Local PC의 계정 정보
- GID: Local PC의 계정 정보
- SERVER_IP: Linux 서버 IP
- SHARE: 3.에서 만든 samba 공유설정
- LOCAL_PATH: SHARE 정보에 해당하는 서버 path를 mount시킬 Local PC의 path
부팅 시 자동적으로 mount되도록 하기 위해여 다음 명령을 terminal에 입력한다.
$ sudo vi /etc/fstab
위 명령어를 실행 후 아래 정보를 맨 밑에 추가해준다.
//${SERVER_IP}/${SHARE} ${LOCAL_PATH} cifs defaults,username=${USERNAME},pass=${PASSWORD},iocharset=utf8,uid=${UID},gid=${GID} 0 0
5. Windows에서 Linux 서버 접근
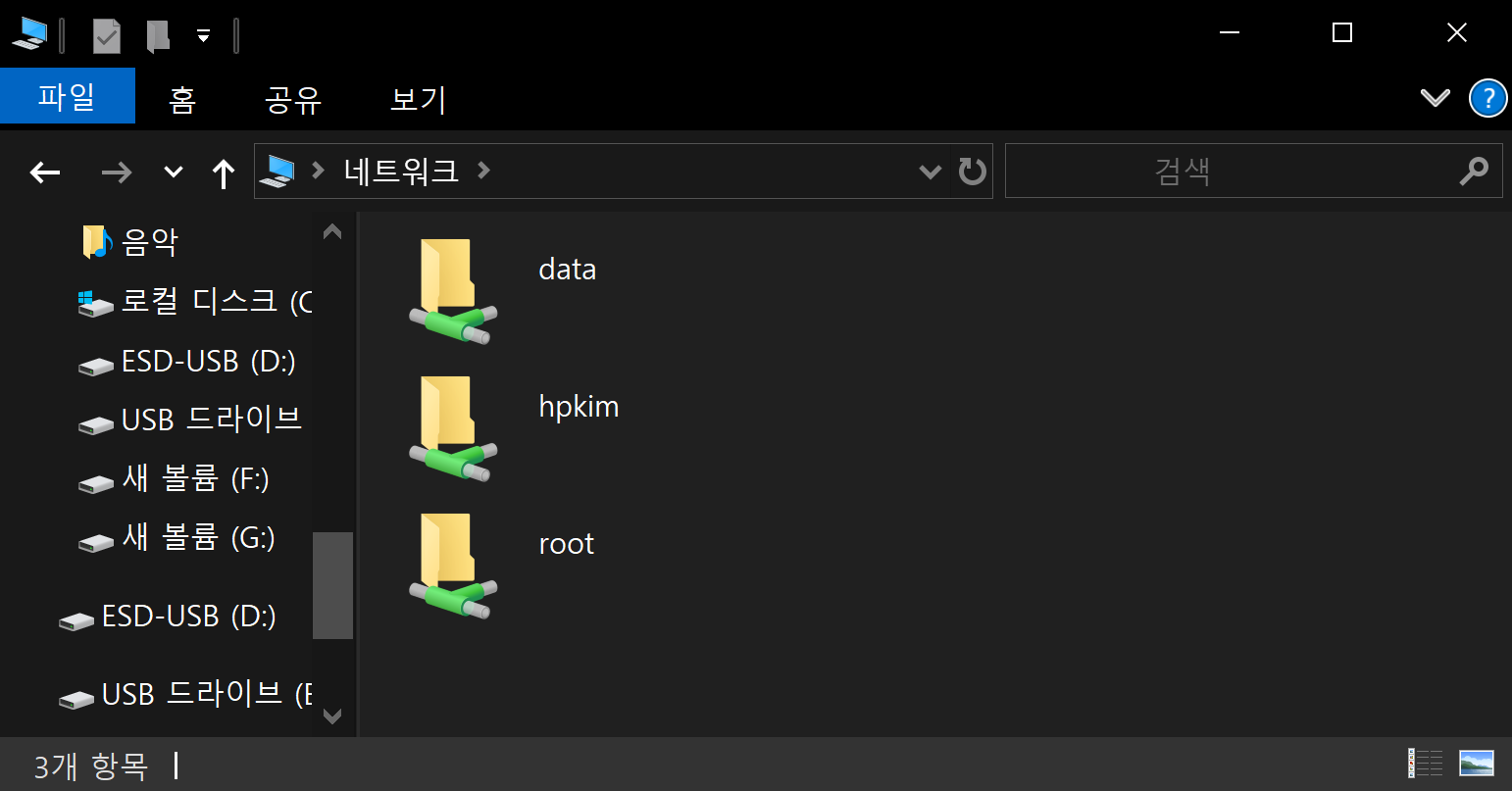
파일 탐색기에서 주소창에 \\SERVER_IP를 입력하여 준다.
로그인 화면이 뜨며 2.에서 만든 Samba 계정 정보를 입력하면 3.에서 만든 SHARE를 발견할 수 있다.
이 중에서 해당 계정이 'valid users'에 들어가있으면 접근할 수 있으며 일반 폴더처럼 사용 가능하다.
로그인 화면이 뜨며 2.에서 만든 Samba 계정 정보를 입력하면 3.에서 만든 SHARE를 발견할 수 있다.
이 중에서 해당 계정이 'valid users'에 들어가있으면 접근할 수 있으며 일반 폴더처럼 사용 가능하다.

